目录
一、k近邻算法
1.1 算法简介
1.2 opencv-k近邻算法
二、cv::ml::KNearest应用
2.1 数据集样本准备
2.2 KNearest应用
2.3 程序编译
2.4 main.cpp全代码
一、k近邻算法
1.1 算法简介
K近邻算法(K-Nearest Neighbor,KNN)基本原理是:
在特征空间中,如果一个样本附近的K个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。具体来说,给定一个训练数据集,对于新的输入实例,KNN算法会在训练数据集中找到与该实例最邻近的K个实例(即K个邻居)。然后,根据这K个邻居的类别进行投票,将票数最多的类别作为新输入实例的预测类别。
KNN算法的优点包括:
- 简单易理解:KNN算法非常直观和简单,易于理解和实现。
- 适用于多分类问题:KNN算法可以很容易地应用于多分类问题。
- 适用于非线性数据:KNN算法对于非线性数据具有良好的适应性。
- 无需训练:KNN算法属于懒惰学习(lazy learning),不需要训练过程,节省了模型训练时间。
KNN算法也存在一些缺点:
- 需要大量内存:KNN算法需要存储所有训练数据,因此在处理大规模数据集时需要大量内存。
- 计算复杂度高:当训练集很大时,KNN算法需要计算测试样本与所有训练样本之间的距离,计算复杂度较高。
- 预测时间长:由于需要计算测试样本与所有训练样本的距离,KNN算法的预测时间较长。
- 敏感度高:KNN算法对于异常值和噪声数据非常敏感,容易受到局部特征的影响。
KNN算法的应用实例包括但不限于手写数字识别、电影推荐系统、人脸识别和疾病诊断等。在这些应用中,KNN算法可以通过计算测试样本与训练样本之间的距离,找到最相似的邻居,并根据邻居的类别进行预测或分类。常用的距离度量方法包括欧式距离、曼哈顿距离、闵可夫斯基距离等。
1.2 opencv-k近邻算法
OpenCV中的K近邻算法(K-Nearest Neighbors, KNN)是一种常用的监督学习算法,主要用于分类和回归问题。该算法基于样本之间的距离来进行分类或回归。
1)对于分类问题,KNN算法将未知样本与训练集中的样本逐个比较距离,并选择距离最近的K个邻居样本。然后,根据这K个邻居样本的标签进行投票,将未知样本归类为票数最多的标签。
2)对于回归问题,KNN算法同样将未知样本与训练集中的样本逐个比较距离,并选择距离最近的K个邻居样本。但是,在回归问题中,KNN算法会取这K个邻居样本的平均值作为未知样本的预测值。
OpenCV中的KNN算法实现包含在ml模块中,函数为cv.ml.KNearest_create()。通过这个函数,你可以创建一个KNN分类器或回归器,并使用训练数据对其进行训练。训练完成后,你可以使用训练好的模型对新的数据进行预测。
k近邻算法是使用的是KNearest类 继承了StatModel类(base类)
class CV_EXPORTS_W KNearest : public StatModel
{
public:
//类代码
};
StatModel类 方法:
训练函数
ret = cv.ml_StatModel.train(samples,layout,responses)
samples: 训练的样本矩阵
layout: 排列方式
responses: 标签矩阵
返还一个bool类型变量来作为是否完成了模型训练
samples 必须为float32类型
layout cv.ml.ROW_SAMPLE 样本按行排列
cv.ml.COL_SAMPLE 按列排列
responses: 单行或者单列的矩阵 类型为int 或者 float
检测函数
retval, res = cv.ml_StatModel.predict(samples)
flags模型标志
res 结果矩阵
samples 输入矩阵
retval: 第一个值得标签
除了使用StatModel提供的通用的预测方法
KNearest类也提供了预测方法
retval,results,neighborResponses,dist = cv.ml_KNearest.findNearest(
sample
k
)
sample: 待预测数据
k: 近邻数
results: 预测结果
neighborResponses: 可以选择输出的每个数据的k个最近邻
dist: 输出k个最近邻的距离
KNN算法的优点包括在线技术(新数据可以直接加入数据集而不必进行重新训练)、理论简单、容易实现、准确性高和对异常值和噪声有较高的容忍度。然而,KNN算法也存在一些缺点,如对于样本容量大的数据集计算量比较大、容易导致维度灾难、样本不平衡时预测偏差比较大,以及k值大小的选择需要依靠经验或交叉验证等。
在OpenCV中,KNN算法可以用于各种图像处理任务,如图像分类、目标检测和模式识别等。通过调整k值和使用不同的距离度量方法,你可以优化KNN算法的性能以适应你的具体任务。
二、cv::ml::KNearest应用
2.1 数据集样本准备
本文为了快速验证使用,采用mnist数据集,参考本专栏博文《C/C++开发,opencv-ml库学习,支持向量机(SVM)应用-CSDN博客》下载MNIST 数据集(手写数字识别),并解压。

同时参考该博文“2.4 SVM(支持向量机)实时识别应用”的章节资料,利用python代码解压t10k-images.idx3-ubyte出图片数据文件。

2.2 KNearest应用
类似ml模块的其他算法一样,创建了一个 cv::ml::KNearest对象,并设置了训练数据和终止条件。接着,我们调用 train 方法来训练决策树模型。最后,我们使用训练好的模型来预测一个新样本的类别。
// 4. 设置并训练KNN模型
// 创建KNN模型
cv::Ptr<cv::ml::KNearest> knn = cv::ml::KNearest::create();
// 设置KNN参数
knn->setAlgorithmType(cv::ml::KNearest::BRUTE_FORCE); // 使用暴力搜索
knn->setIsClassifier(true); // 设置为分类器
knn->setDefaultK(3); // 设置K值
// 训练KNN模型
knn->train(trainingData, cv::ml::ROW_SAMPLE, labelsMat);
//同样预测函数调用
cv::Mat testResp;
float response = knn->predict(testData,testResp);
//存储模型,文件名借用了博文的命名,不必在意
knn->save("mnist_svm.xml"); 训练及测试过的算法模型,保存输出(.xml),然后调用。PS,训练图片解压读取请参见C/C++开发,opencv-ml库学习,支持向量机(SVM)应用-CSDN博客的“2.4 SVM(支持向量机)实时识别应用”章节。
cv::Ptr<cv::ml::KNearest> kkn = cv::ml::StatModel::load<cv::ml::KNearest>("mnist_svm.xml");
//read img 28*28 size
cv::Mat image = cv::imread(fileName, cv::IMREAD_GRAYSCALE);
//uchar->float32
image.convertTo(image, CV_32F);
//image data normalization
image = image / 255.0;
//28*28 -> 1*784
image = image.reshape(1, 1);
//预测图片
float ret = knn->predict(image);
std::cout << "predict val = "<< ret << std::endl;2.3 程序编译
和讲述支持向量机(SVM)应用的博文编译类似,采用opencv+mingw+makefile方式编译:
#/bin/sh
#win32
CX= g++ -DWIN32
#linux
#CX= g++ -Dlinux
BIN := ./
TARGET := opencv_ml04.exe
FLAGS := -std=c++11 -static
SRCDIR := ./
#INCLUDES
INCLUDEDIR := -I"../../opencv_MinGW/include" -I"./"
#-I"$(SRCDIR)"
staticDir := ../../opencv_MinGW/x64/mingw/staticlib/
#LIBDIR := $(staticDir)/libopencv_world460.a\
# $(staticDir)/libade.a \
# $(staticDir)/libIlmImf.a \
# $(staticDir)/libquirc.a \
# $(staticDir)/libzlib.a \
# $(wildcard $(staticDir)/liblib*.a) \
# -lgdi32 -lComDlg32 -lOleAut32 -lOle32 -luuid
#opencv_world放弃前,然后是opencv依赖的第三方库,后面的库是MinGW编译工具的库
LIBDIR := -L $(staticDir) -lopencv_world460 -lade -lIlmImf -lquirc -lzlib \
-llibjpeg-turbo -llibopenjp2 -llibpng -llibprotobuf -llibtiff -llibwebp \
-lgdi32 -lComDlg32 -lOleAut32 -lOle32 -luuid
source := $(wildcard $(SRCDIR)/*.cpp)
$(TARGET) :
$(CX) $(FLAGS) $(INCLUDEDIR) $(source) -o $(BIN)/$(TARGET) $(LIBDIR)
clean:
rm $(BIN)/$(TARGET)
make编译,make clean 清除可重新编译。

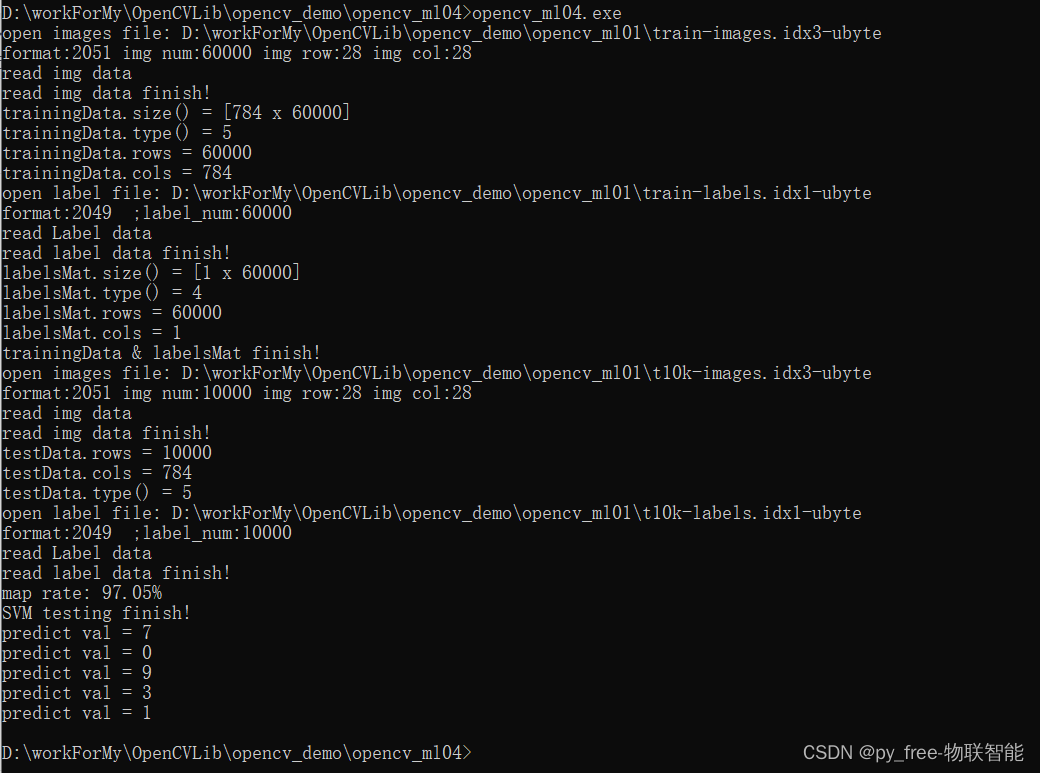
运行效果,同样数据样本,相比前面博文所述算法训练结果,其准确率有了较大改善,大家可以尝试调整参数验证:

2.4 main.cpp全代码
main.cpp源代码,由于是基于前三篇博文支持向量机(SVM)应用、决策树(DTrees)应用、随机森林(RTrees)应用基础上,快速移用实现的,有很多支持向量机(SVM)应用或决策树(DTrees)的痕迹,采用的数据样本也非较合适的,仅仅是为了阐述c++ opencv K近邻算法(KNearest)应用说明。
#include <opencv2/opencv.hpp>
#include <opencv2/ml/ml.hpp>
#include <opencv2/imgcodecs.hpp>
#include <iostream>
#include <vector>
#include <iostream>
#include <fstream>
int intReverse(int num)
{
return (num>>24|((num&0xFF0000)>>8)|((num&0xFF00)<<8)|((num&0xFF)<<24));
}
std::string intToString(int num)
{
char buf[32]={0};
itoa(num,buf,10);
return std::string(buf);
}
cv::Mat read_mnist_image(const std::string fileName) {
int magic_number = 0;
int number_of_images = 0;
int img_rows = 0;
int img_cols = 0;
cv::Mat DataMat;
std::ifstream file(fileName, std::ios::binary);
if (file.is_open())
{
std::cout << "open images file: "<< fileName << std::endl;
file.read((char*)&magic_number, sizeof(magic_number));//format
file.read((char*)&number_of_images, sizeof(number_of_images));//images number
file.read((char*)&img_rows, sizeof(img_rows));//img rows
file.read((char*)&img_cols, sizeof(img_cols));//img cols
magic_number = intReverse(magic_number);
number_of_images = intReverse(number_of_images);
img_rows = intReverse(img_rows);
img_cols = intReverse(img_cols);
std::cout << "format:" << magic_number
<< " img num:" << number_of_images
<< " img row:" << img_rows
<< " img col:" << img_cols << std::endl;
std::cout << "read img data" << std::endl;
DataMat = cv::Mat::zeros(number_of_images, img_rows * img_cols, CV_32FC1);
unsigned char temp = 0;
for (int i = 0; i < number_of_images; i++) {
for (int j = 0; j < img_rows * img_cols; j++) {
file.read((char*)&temp, sizeof(temp));
//svm data is CV_32FC1
float pixel_value = float(temp);
DataMat.at<float>(i, j) = pixel_value;
}
}
std::cout << "read img data finish!" << std::endl;
}
file.close();
return DataMat;
}
cv::Mat read_mnist_label(const std::string fileName) {
int magic_number;
int number_of_items;
cv::Mat LabelMat;
std::ifstream file(fileName, std::ios::binary);
if (file.is_open())
{
std::cout << "open label file: "<< fileName << std::endl;
file.read((char*)&magic_number, sizeof(magic_number));
file.read((char*)&number_of_items, sizeof(number_of_items));
magic_number = intReverse(magic_number);
number_of_items = intReverse(number_of_items);
std::cout << "format:" << magic_number << " ;label_num:" << number_of_items << std::endl;
std::cout << "read Label data" << std::endl;
//data type:CV_32SC1,channel:1
LabelMat = cv::Mat::zeros(number_of_items, 1, CV_32SC1);
for (int i = 0; i < number_of_items; i++) {
unsigned char temp = 0;
file.read((char*)&temp, sizeof(temp));
LabelMat.at<unsigned int>(i, 0) = (unsigned int)temp;
}
std::cout << "read label data finish!" << std::endl;
}
file.close();
return LabelMat;
}
//change path for real paths
std::string trainImgFile = "D:\\workForMy\\OpenCVLib\\opencv_demo\\opencv_ml01\\train-images.idx3-ubyte";
std::string trainLabeFile = "D:\\workForMy\\OpenCVLib\\opencv_demo\\opencv_ml01\\train-labels.idx1-ubyte";
std::string testImgFile = "D:\\workForMy\\OpenCVLib\\opencv_demo\\opencv_ml01\\t10k-images.idx3-ubyte";
std::string testLabeFile = "D:\\workForMy\\OpenCVLib\\opencv_demo\\opencv_ml01\\t10k-labels.idx1-ubyte";
void train_SVM()
{
//read train images, data type CV_32FC1
cv::Mat trainingData = read_mnist_image(trainImgFile);
//images data normalization
trainingData = trainingData/255.0;
std::cout << "trainingData.size() = " << trainingData.size() << std::endl;
std::cout << "trainingData.type() = " << trainingData.type() << std::endl;
std::cout << "trainingData.rows = " << trainingData.rows << std::endl;
std::cout << "trainingData.cols = " << trainingData.cols << std::endl;
//read train label, data type CV_32SC1
cv::Mat labelsMat = read_mnist_label(trainLabeFile);
std::cout << "labelsMat.size() = " << labelsMat.size() << std::endl;
std::cout << "labelsMat.type() = " << labelsMat.type() << std::endl;
std::cout << "labelsMat.rows = " << labelsMat.rows << std::endl;
std::cout << "labelsMat.cols = " << labelsMat.cols << std::endl;
std::cout << "trainingData & labelsMat finish!" << std::endl;
// //create SVM model
// cv::Ptr<cv::ml::SVM> svm = cv::ml::SVM::create();
// //set svm args,type and KernelTypes
// svm->setType(cv::ml::SVM::C_SVC);
// svm->setKernel(cv::ml::SVM::POLY);
// //KernelTypes POLY is need set gamma and degree
// svm->setGamma(3.0);
// svm->setDegree(2.0);
// //Set iteration termination conditions, maxCount is importance
// svm->setTermCriteria(cv::TermCriteria(cv::TermCriteria::EPS | cv::TermCriteria::COUNT, 1000, 1e-8));
// std::cout << "create SVM object finish!" << std::endl;
// std::cout << "trainingData.rows = " << trainingData.rows << std::endl;
// std::cout << "trainingData.cols = " << trainingData.cols << std::endl;
// std::cout << "trainingData.type() = " << trainingData.type() << std::endl;
// // svm model train
// svm->train(trainingData, cv::ml::ROW_SAMPLE, labelsMat);
// std::cout << "SVM training finish!" << std::endl;
// // 创建决策树对象
// cv::Ptr<cv::ml::DTrees> dtree = cv::ml::DTrees::create();
// dtree->setMaxDepth(30); // 设置树的最大深度
// dtree->setCVFolds(0);
// dtree->setMinSampleCount(1); // 设置分裂内部节点所需的最小样本数
// std::cout << "create dtree object finish!" << std::endl;
// // 训练决策树--trainingData训练数据,labelsMat训练标签
// cv::Ptr<cv::ml::TrainData> td = cv::ml::TrainData::create(trainingData, cv::ml::ROW_SAMPLE, labelsMat);
// std::cout << "create TrainData object finish!" << std::endl;
// if(dtree->train(td))
// {
// std::cout << "dtree training finish!" << std::endl;
// }else{
// std::cout << "dtree training fail!" << std::endl;
// }
// // 3. 设置并训练随机森林模型
// cv::Ptr<cv::ml::RTrees> rf = cv::ml::RTrees::create();
// rf->setMaxDepth(30); // 设置决策树的最大深度
// rf->setMinSampleCount(2); // 设置叶子节点上的最小样本数
// rf->setTermCriteria(cv::TermCriteria(cv::TermCriteria::EPS + cv::TermCriteria::COUNT, 10, 0.1)); // 设置终止条件
// rf->train(trainingData, cv::ml::ROW_SAMPLE, labelsMat);
// 4. 设置并训练KNN模型
// 创建KNN模型
cv::Ptr<cv::ml::KNearest> knn = cv::ml::KNearest::create();
// 设置KNN参数
knn->setAlgorithmType(cv::ml::KNearest::BRUTE_FORCE); // 使用暴力搜索
knn->setIsClassifier(true); // 设置为分类器
knn->setDefaultK(3); // 设置K值
// 训练KNN模型
knn->train(trainingData, cv::ml::ROW_SAMPLE, labelsMat);
// svm model test
cv::Mat testData = read_mnist_image(testImgFile);
//images data normalization
testData = testData/255.0;
std::cout << "testData.rows = " << testData.rows << std::endl;
std::cout << "testData.cols = " << testData.cols << std::endl;
std::cout << "testData.type() = " << testData.type() << std::endl;
//read test label, data type CV_32SC1
cv::Mat testlabel = read_mnist_label(testLabeFile);
cv::Mat testResp;
// float response = svm->predict(testData,testResp);
// float response = dtree->predict(testData,testResp);
// float response = rf->predict(testData,testResp);
float response = knn->predict(testData,testResp);
// std::cout << "response = " << response << std::endl;
testResp.convertTo(testResp,CV_32SC1);
int map_num = 0;
for (int i = 0; i <testResp.rows&&testResp.rows==testlabel.rows; i++)
{
if (testResp.at<int>(i, 0) == testlabel.at<int>(i, 0))
{
map_num++;
}
// else{
// std::cout << "testResp.at<int>(i, 0) " << testResp.at<int>(i, 0) << std::endl;
// std::cout << "testlabel.at<int>(i, 0) " << testlabel.at<int>(i, 0) << std::endl;
// }
}
float proportion = float(map_num) / float(testResp.rows);
std::cout << "map rate: " << proportion * 100 << "%" << std::endl;
std::cout << "SVM testing finish!" << std::endl;
//save svm model
// svm->save("mnist_svm.xml");
// dtree->save("mnist_svm.xml");
// rf->save("mnist_svm.xml");
knn->save("mnist_svm.xml");
}
void prediction(const std::string fileName,cv::Ptr<cv::ml::KNearest> knn)
// void prediction(const std::string fileName,cv::Ptr<cv::ml::DTrees> dtree)
// void prediction(const std::string fileName,cv::Ptr<cv::ml::SVM> svm)
{
//read img 28*28 size
cv::Mat image = cv::imread(fileName, cv::IMREAD_GRAYSCALE);
//uchar->float32
image.convertTo(image, CV_32F);
//image data normalization
image = image / 255.0;
//28*28 -> 1*784
image = image.reshape(1, 1);
//预测图片
// float ret = dtree->predict(image);
float ret = knn->predict(image);
std::cout << "predict val = "<< ret << std::endl;
}
std::string imgDir = "D:\\workForMy\\OpenCVLib\\opencv_demo\\opencv_ml01\\t10k-images\\";
std::string ImgFiles[5] = {"image_0.png","image_10.png","image_20.png","image_30.png","image_40.png",};
void predictimgs()
{
//load svm model
// cv::Ptr<cv::ml::SVM> svm = cv::ml::StatModel::load<cv::ml::SVM>("mnist_svm.xml");
//load DTrees model
// cv::Ptr<cv::ml::DTrees> dtree = cv::ml::StatModel::load<cv::ml::DTrees>("mnist_svm.xml");
// cv::Ptr<cv::ml::RTrees> rf = cv::ml::StatModel::load<cv::ml::RTrees>("mnist_svm.xml");
cv::Ptr<cv::ml::KNearest> kkn = cv::ml::StatModel::load<cv::ml::KNearest>("mnist_svm.xml");
for (size_t i = 0; i < 5; i++)
{
prediction(imgDir+ImgFiles[i],kkn);
}
}
int main()
{
train_SVM();
predictimgs();
return 0;
}